NLP学习
神经网络
梯度下降
使用误差方程来计算预测值和真实值的差距,不断调整神经网络中连接的权重。
主要是通过梯度下降的方法来找到局部最优的权重值。
补充
one-hot编码
- 为什么要binarize分类特征?使用one-hot编码,将离散特征的取值扩展到了欧式空间,离散特征的某个取值就对应欧式空间的某个点。
- Why do we embed the feature vectors in the Euclidean space?是因为,在回归,分类,聚类等机器学习算法中,特征之间距离的计算或相似度的计算是非常重要的,而我们常用的距离或相似度的计算都是在欧式空间的相似度计算,计算余弦相似性,基于的就是欧式空间。
- 将离散型特征进行one-hot编码的作用,是为了让距离计算更合理,但如果特征是离散的,并且不用one-hot编码就可以很合理的计算出距离,那么就没必要进行one-hot编码,比如,该离散特征共有1000个取值,我们分成两组,分别是400和600,两个小组之间的距离有合适的定义,组内的距离也有合适的定义,那就没必要用one-hot 编码。
word2vec
在此之前,nlp是将字词转为one-hot编码类型的词向量。缺点在于,数据稀疏性非常高,维度很多,容易造成维度灾难。存在语义鸿沟,无法体现词与词之间的关系。
神经网络的训练是有监督的学习,因此要给定输入值和输出值来训练神经网络,而我们最终要获得的是隐藏层的权重矩阵。因为隐藏层的输出事实上是每个输入单词的 “嵌入词向量”。计算的时候,并不会进行矩阵乘法,而是直接找1所在的地方,直接读取词向量。 
RNN
是受到人的思考方式的启发,当人看到一个句子时,对单词的理解是基于对上一个单词的认知,因此这个序列关系/上下文关系对单词的理解很有帮助。 RNN是一个具有有限loop的神经网络,如下图所示,$x_t$为输入,$h_t$为输出,$A$是RNN网络结构。 
将上面这个loop展开后可以看到: 
RNN的优点:
- chain-like的网络结构可以让lists和sequences之间的关系得到学习。
- 可应用于以下方面:speech recognition, language modeling, translation, image captioning… The list goes on.
LSTM
LSTM是一种特殊的RNN,大多数运用RNN成功的例子都是基于LSTM完成的。 RNN能够通过上下文的关系来预测,但是如果上下文距离很遥远,RNN是无法预测的,比如“I grew up in France… I speak fluent French.”。此处French需要France的relevant information,但是两个单词位于不同的句子中,距离非常遥远。
- 为什么RNN无法预测? 在理论上,RNN可以通过configure参数来扩大读取的面积,但是在实际中,RNN并不能handle这种预测,因为depth过深,时间上是无法完成。
相较于RNN,LSTM不同的是在网络结构中,有多种interacting way 
LSTM的core idea
LSTM具有三种gates,通过sigmoid函数[0,1]来可计算component通过的概率,以此来protect和control这些cell state
具体步骤:
- forget gate layer,用一个$f_t$来forget掉我们希望忘记的previous subject的info
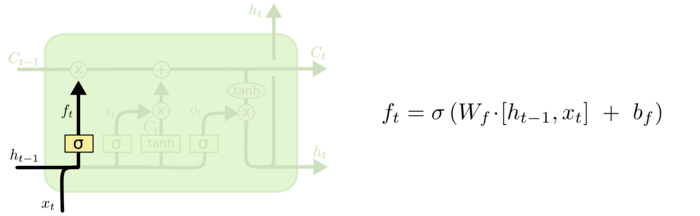
- input gate layer,用于决定我们要更新==哪一个值==,创建一个new candidate values$C_t$介入state。
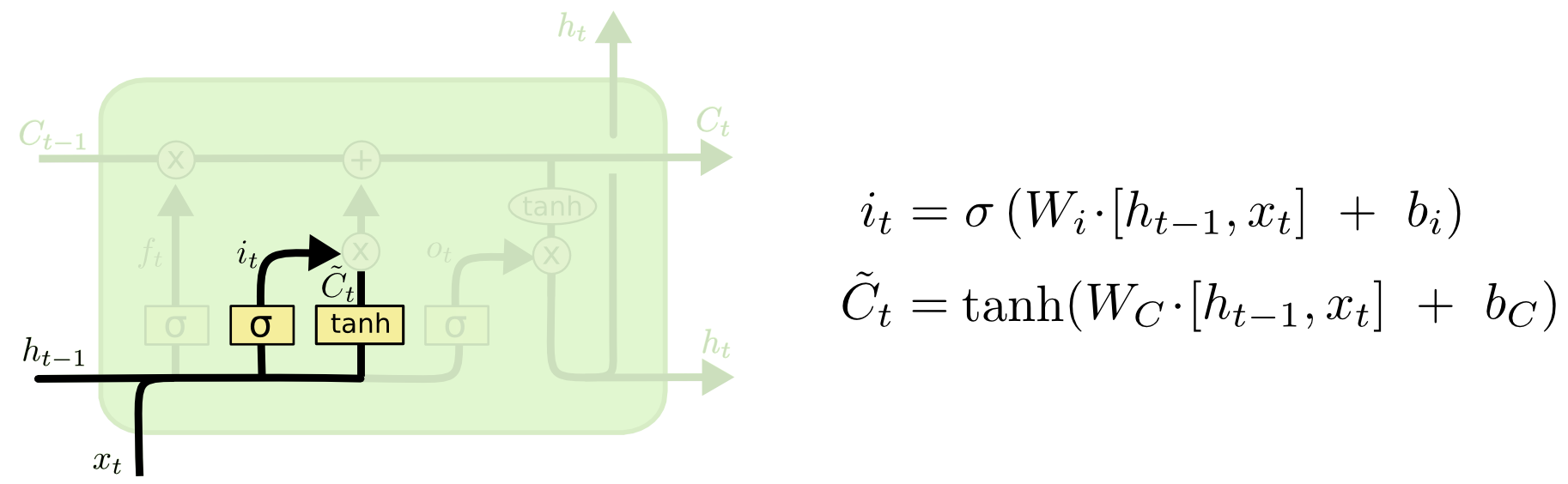
- output gate layer, Then we add $i_t * C̃t$,然后和前面已遗忘的$C{t-1}$state相加,$C_t = f_t * C_{t-1} + i_t * C̃_t$
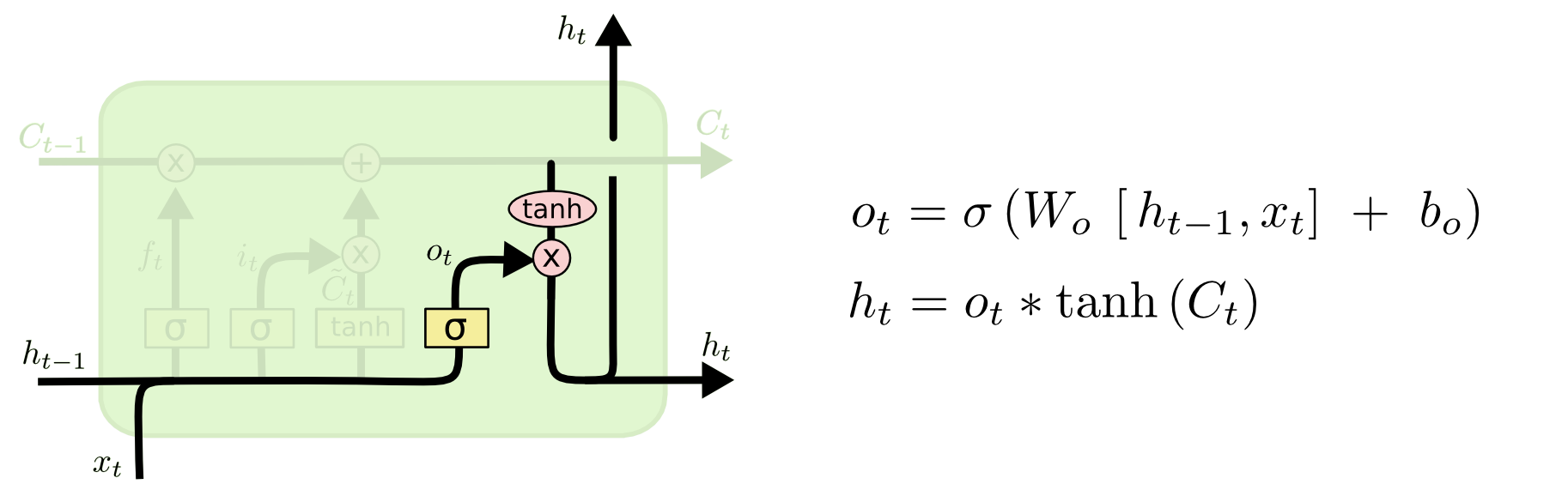
接下来看神经元内最上方的$C{t−1}$.与$a{t−1}$类似,Ct−1也携带着上文的信息。进入神经元后,Ct−1首先会与遗忘权重逐元素相乘,可以想见,由于遗忘权重中值得特点,因此与该权重相乘之后Ct−1 中绝大部分的值会变的非常接近0或者非常接近该位置上原来的值。这非常像一扇门,它会决定让哪些Ct−1的元素通过以及通过的比例有多大。反映到实际中,就是对Ct−1中携带的信息进行选择性的遗忘(乘以非常接近0的数)和通过(乘以非常接近1的数),亦即乘以一个权重。
理解了遗忘门的作用之后,其他两个门也就比较好理解了。输入门则是对输入信息进行限制,而输入信息就是RNN中的前向运算的结果。经过输入门处理后的信息就可以添加到经过遗忘门处理的上文信息中去,这就是神经元内唯一一个逐元素相加的工作。
LSTM的variants
- 将$C_{t-1}$拼接到$h_{t-1}, x_t$后面。
Attention机制
注意力模型,这个说到底还只是一个资源分配模型,在某个特定时刻,你的注意力总是集中在画面中的某个焦点部分,而对其它部分视而不见。
Encoder-Decoder框架
Encoder-Decoder模型中的编码,就是将输入序列转化成一个固定长度的向量;解码,就是将之前生成的固定向量再转化成输出序列。 
缺点:在编码时,后输入的语义信息会覆盖前面输入的语义信息,导致Encoder得到的编码C是有损信息。因而,在解码时,解析的数据本身就不够准确。
为了解决上面的弊端,就需要用到Attention Model。在编码时,让code C拥有一个注意力范围。
注意力分配概率分布值
 可以采用
可以采用
\(c_i = \sum _{j=1}^{T_x}{\alpha_{ij}h_{j}}\) 其中: \(\alpha_{ij} = \frac{exp(e_{ij})}{\sum_{k=1}^{T_x}{exp(e_{ik})}}\) \(e_{ij} = a(s_{i-1}, h_j)\)
在上面公式中 $h_j$是Encoder层的隐层第j时刻的输出,$s_{i−1}$是Decoder层第$i−1$时刻隐层的输出。可以发现在计算 $c_i$的模型实际上是一个线性模型,而且$c_i$事实上是Encoder层中各时刻隐层的输出的加权平均值。
因此引入Attention 机制,在机器翻译中,模型会自己去学得在不同时刻不同的权重系数$a_{ij}$
Bi-LSTM
参考
- http://colah.github.io/posts/2015-08-Understanding-LSTMs/
- https://www.cnblogs.com/jiangxinyang/p/9362922.html
- https://www.cnblogs.com/jiangxinyang/p/9362922.html
- https://www.cnblogs.com/jiangxinyang/p/9367497.html